Update 1¶
Meeting Time:¶
Team Invoca decided to meet on Fridays at 4pm. Smaller meetings are sometimes called during the week among students.
Dataset:¶
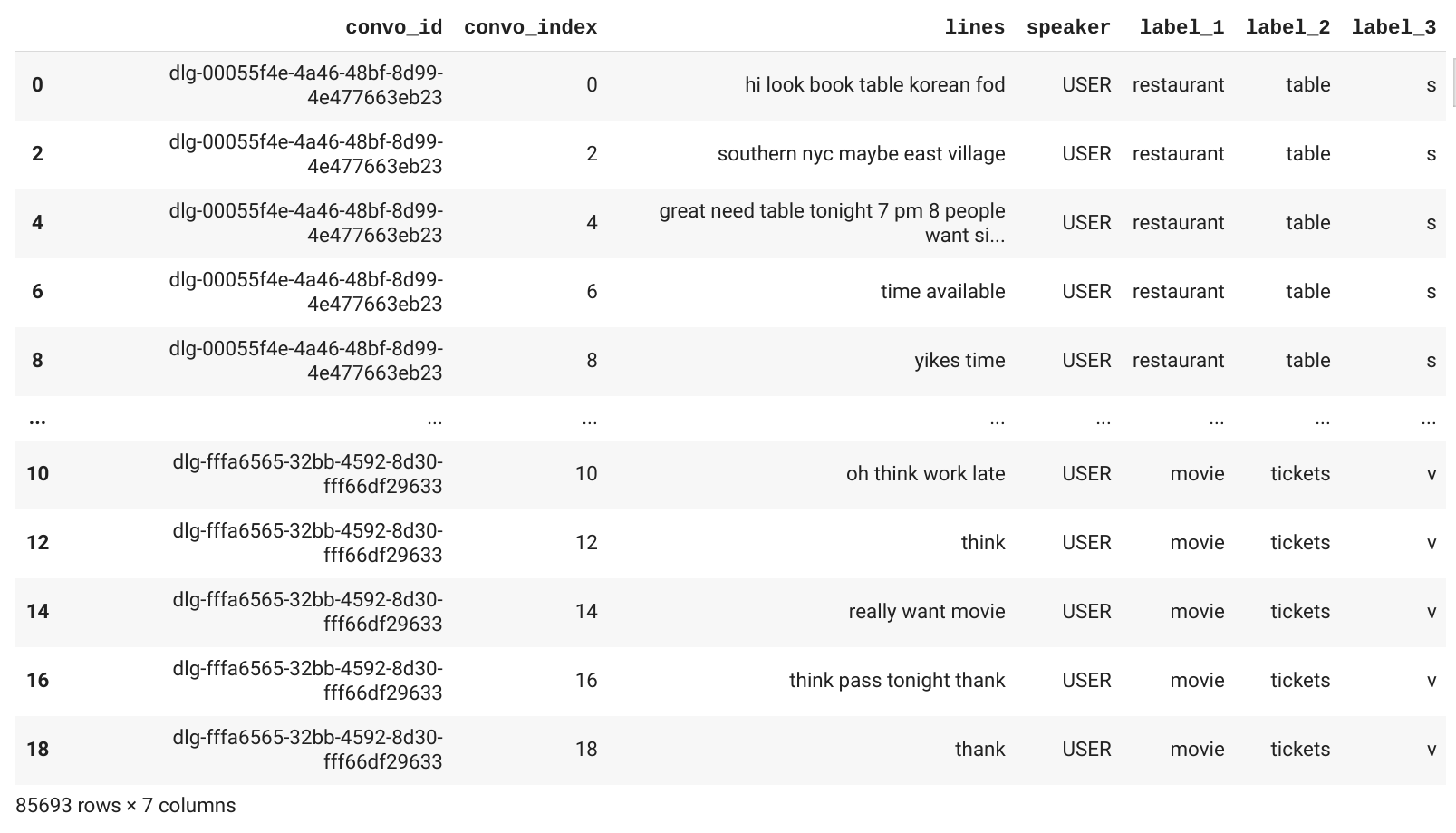
We’re using the open-source Google Taskmaster-1 dataset, which consists of 13,215 task-based dialogs created between a customer and an agent having a conversation recorded in text about one of the following six topics: ordering pizza, creating auto repair appointments, setting up ride service, ordering movie tickets, ordering coffee drinks, and making restaurant reservations.
Project Ideas:¶
As a group, we decided on two broad ideas: making a “notetaking” app that collects and displays the key elements in a conversation or making a “categorizing” app that can classify the general labels associated with a conversation, which can then be extended to a chatbot later on. Regardless of which we end up choosing, we need to have machine learning models to learn from the data and a chat client hooked up to a server to send new data to the database and demo our models.
Model Progress:¶
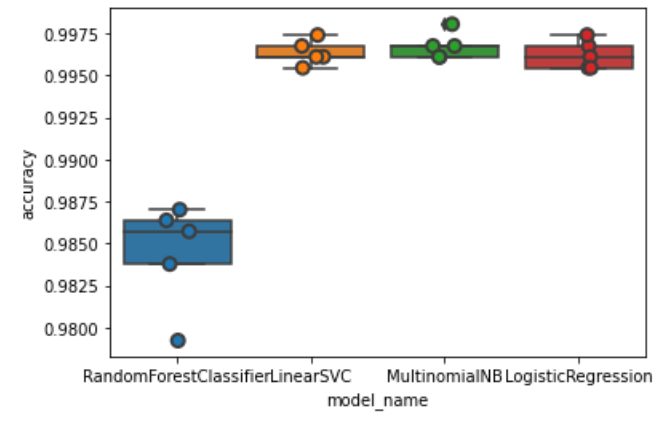
Once we saw that traditional ML methods like SVC, NB, RF, and Logistic Regression yielded high accuracy, (around 98%) we decided to pursue these models and begin generating datasets of labeled lines, in order to generate predictions based only on individual lines. Our procedure was to use the less fine grained, conversation level labels of our data and to generate a dataframe where each row contains a line with the corresponding conversation label. This was a simple naive approach to get some initial results, and as expected the accuracy of these models was not very high. In order to get improved results we plan on generating a new dataframe, this time using the less fine grained annotations from inside the conversation. Because not every line has an annotation associated with it, we are going to use null labels for those lines.
Lastly, once this task is accomplished and we have the results, if we need further improvement, we plan on generating a cumulative dataframe. This dataframe will simulate the cumulative nature of the chat logs, where more information will be available for the model to make predictions as the conversation evolves. Thus, each row will include the current line and every line before it, as well as the current annotation and every annotation before it. If any of the models we train on this last dataset has high accuracy, we will begin work on implementing an integrated system with the chat client and go from there.
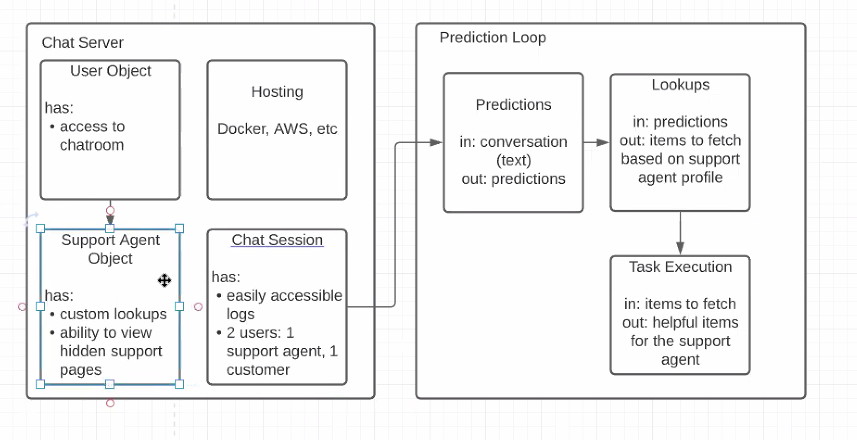
Chat Client/Server Progress:¶
For the user to interact with our model and directly add input we created a multi-user group chat application in Python. We created the user-interface through a Python GUI library called Tkinter to give the user a more interactive application. This way we would be able to hide all the critical functionality away from the user and present them with a simple front-end that is easy to use. This application will allow multiple users to simultaneously connect to the same server and send messages in between each other. In order to have multiple clients we imported the thread library to be able to run parallel tasks so we do not block the main thread. We wanted our application to be able to keep listening for and accepting new clients while sending messages, so we created a thread for accetping new clients and another thread for handling messages. All the messages that are sent are routed to our database that we created using MongoDB. MongoDB has the benefit of being a NoSQL database meaning it uses JSON-like documents and is much faster than most traditional SQL databases. The chat log from this database will be fed into our prediction loop where we take the raw text as input and output our predictions.