Update1¶
Overview¶
This quarter our team worked with local Insurtech company Carpe Data. Carpe Data uses real-time data and predictive scoring for claims, underwriting and book assessment. Our team is building a model to predict if a website contains information about an arrest. Our data set consists of 5 GB of raw html code. Each row has a website’s html code, the url, and a label of 1 or 0. There are 34,307 rows of training data and 8,577 rows of testing data. The data set was web scraped and then labeled for the content. If the label was ‘Potentially unlawful activity’, a new label of 1 was assigned, otherwise a label of 0 was assigned. We aim to accurately classify new websites as either 1 or 0, while striving to avoid false negatives - since our model is for information retrieval. After classification, we aim to extract the date of the arrest and the arrest code.
Progress¶
Given our large dataset, we started by examining a random sample. Using pandas, we randomly selected 5% of the dataset. From here we were able to prototype a function to parse through the html, break the sentence up into individual words, and then remove all punctuation, case, and stopwords (words which convey not meaningful information). This data we fed into a TFIDFvectorizer – TFIDF means term frequency - inverse document frequency. In short, the TFIDF vectorizer turns each document into a numerical feature, weighting the words by their frequency across the entire set of documents. This decreases the importance of very common and meaningless words while excluding words that occur above or below our desired frequency all together. With our new vectorized features we were able to train a logistic regression model to promising results: 94% mean accuracy, 87% recall and 89% precision.
Seeing the early success of our parsing function and a fairly simplistic model, we expanded our methods to the entire dataset. Our basic parsing/cleaning function was beefed up into a script that could run overnight. Parsing the html, tokenizing the strings, and then removing unnecessary attributes is extremely computationally expensive; our training data set took approximately 15 hours to be cleaned. In the end our training dataset was reduced from 4Gb to 628 MB and our test dataset was reduced from 1Gb to 151 MB. Training a logistic regression model on the full dataset again yielded excellent results - 94% accuracy, 94% recall, and 85% precision.
Sampling our Data¶

Cleaning Function¶
def clean_and_tokenize(x):
"""Takes in string of html codes and returns cleaned and tokenized
requires BeautifulSoup, nltk.word_tokenize, nltk.corpus stopwords"""
#stemmer = PorterStemmer()
soup = BeautifulSoup(x, 'lxml') #parses html
text = soup.get_text() #convert to text
tokens = word_tokenize(text) #tokenize
stop_words = set(stopwords.words('english')) #remove stop words
# remove all tokens that are not alphabetic
words = [word.lower() for word in tokens if word.isalpha() and word not in stop_words]
w = " ".join(words)
return w
Logistic Regression¶
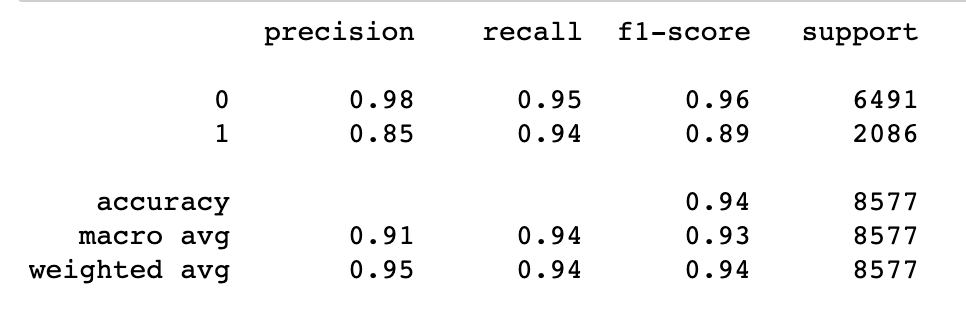
The classification report of our logistic regression showed a promissing model.
Examing the words associated with the largest coefficients of our model showed some seemingly intuitive results.

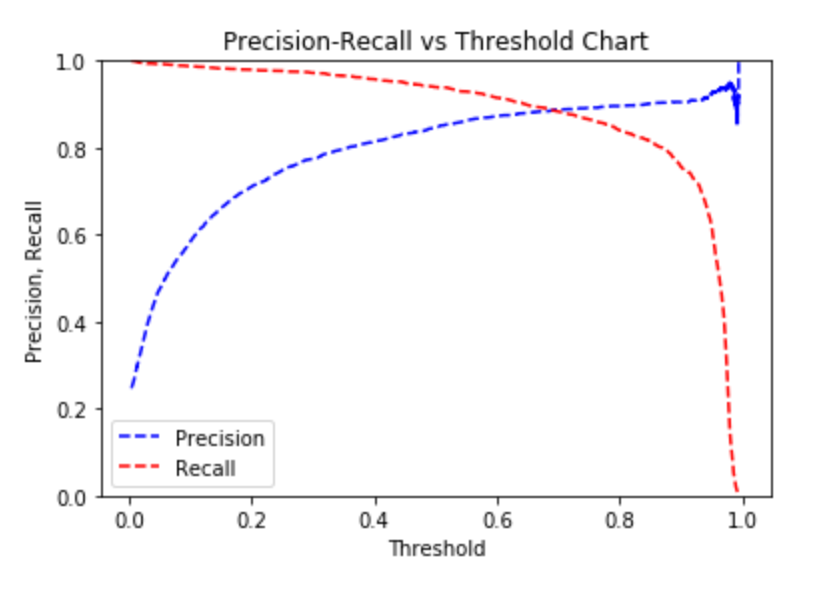
The precision-recall curve shows our model needs very little hyperparameter tuning for our desired goal of maximizing recall.
Challenges¶
Our biggest challenge so far is the sheer amount of time it takes to clean data. Our cleaning and tokenization script took almost 15 hours to run on the data set (on a laptop). Bringing this time down would be ideal so we could experiment with other forms of tokenization (such as bigrams or trigrams). This could be accomplished through employing cloud computing infrastructure, parallelization, and increasing the efficiency of our code.
Next Steps¶
Our next step is to fine tune our model and experiment with other models such as Random Forests, Boosted Trees, Naive Bayes, and Neural Networks. We are going to empoy hyperparameter tuning to maximize the recall of our potential models and then select our best performer. After we have found an optimal model, we are going to implement text to obtain arrest codes and arrest dates from our positively classified documents. To do this we are going to start with regular expressions and then potentially move on to more advanced custom functions or model based solutions.