Update 2¶
Center for Science and Engineering Partnerships (CSEP) Project¶

Capstone Members¶
Manny Medrano, Andrea Anez, Romtin Toranji, Karanveer Benipal
Faculty¶
Alexander Franks, Lubi Lenaburg, Joshua Bang
Introduction¶
The CSEP Alumni Tracking Project tracks students graduating from 2000 - 2018 from the University of California, Santa Barbara. The overall goal of tracking students is monitoring opportunities UCSB provides and the impact on student outcomes.
The data comes from a mix of sources: online - LinkedIn, personal websites, and professional organizations - and UCSB’s information about students. While not all of the data was accessed through an automated system, some of it required some manual revisions to determine if a student’s data is updated. So while we collected from some of the sources listed above, there will exist some type of error whether it is a simple misspelling of a word to texts existing in an integer column.
The organization providing the data does not have an overall goal for the outcome of the data: the CSEP group is free to explore any possible avenue for the data within reason.
Accessing the Secure Research Compute Environment (SCRE)¶
SCRE is a way for the team to access the data without having any breaches in the security of the data itself. Because the data we are using is of actual past UCSB alumni, we don’t want to expose any sensitive information of each individual. While on SCRE, we’re not only able to access this information, but we’re also able to play around with it in python code on our virtual machines!
More specifically, each capstone member is assigned a specific Virtual Machine (VM) that allows the designated user to access the data through that VM. An important aspect to note is that while UCSB maintains a complete and thorough alumni dataset, not all of it is allocated to our team. The Family Educational Rights and Privacy Act (FERPA) restricts the alumni and student information that institutions such as UCSB can release. For this reason, our team only works with a portion of the alumni dataset in a secure environment as a means to respect the privacy of UCSB alumni and students.
Cleaning Up the Data¶
The first and arguably most important step in any project is cleaning up the dataset. CSEP provided a very detailed, yet messy dataset. Containing five total files, the datasets included over 30,000 students and their accomplishments over the years. Getting everyone on the same page, the cleaned-up data can be accessed via a function call. This way we can ensure reproducibility in the results.
Standardizing Dates¶
Academic choices and Careers contained numerous corresponding months, days, and years in different columns. In some instances, the months were given as seasons. Taking that into account, the months were replaced with a standardized form using a dictionary. Then months, days, and years were combined and converted into a DateTime format. Next, the redundant dates were dropped. The missing values were imputed based on the mode for either the month or the year.
Capitalization, Punctuation, and Typos¶
CSEP provided hand-entered data. Unfortunately, humans are not perfect and errors are to be expected. The most common error is capitalization. Python and many other programming languages interpret different capitalizations of the same words as different. The quick and most effective fix was to capitalize everything. Also, programming languages can’t overcome different punctuation. Therefore, non-essential punctuation was stripped to standardize the data. Finally, everyone makes typos. Pesky and annoying, they can completely alter a dataset. While an ongoing process, any found typos are being corrected.
Missing Data¶
As mentioned in standardized dates, there is missing data. Also, most of the missing data comes from the high school dataset. While not significant, the best practice is to insert any good assumptions. Many techniques were used, but the most effective is using a forward fill on objects regarding the same ID.
Adding Data¶
The data currently available does not extend much further beyond student information. Wanting to know more about the graduate and professional schools attended, ranking data was web-scrapped from U.S. News and added to the institutional data.
Predicting Level of Job Title¶
Question¶
Is a student’s first job out of college dependent on what they did in college?
Data and Modeling¶
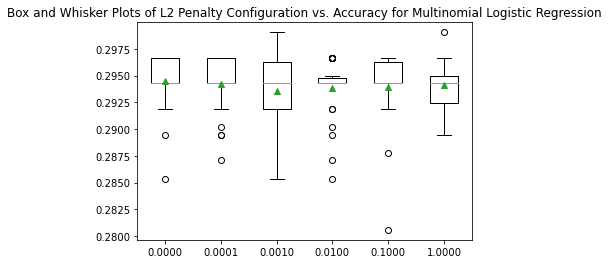
The CSEP data combined to form a data frame containing the quantifiable characteristics of their highschool (SAT Quintile, Total Enrollment, Graduates, etc.), their degree and college characteristics (Honors Program, Study Abroad, STEM, College, etc.), their characteristics (Gender), and their level of job title. The level of job title is divided into sixteen categories from intern to owner/CEO. Based on their job title and description, everyone was placed into a level. After dropping all rows with Null data, there were over five thousand rows to model on. The level of Job Title was converted into numerical labels and all other categorical features were one-hot encoded. Then a multinomial logistic regression model predicted a graduate’s first job out of college. Finally, cross-validation tuned the results. The model predicts with 30% accuracy, three times better than a random guess.
‘Graduate’ Degrees¶
Question¶
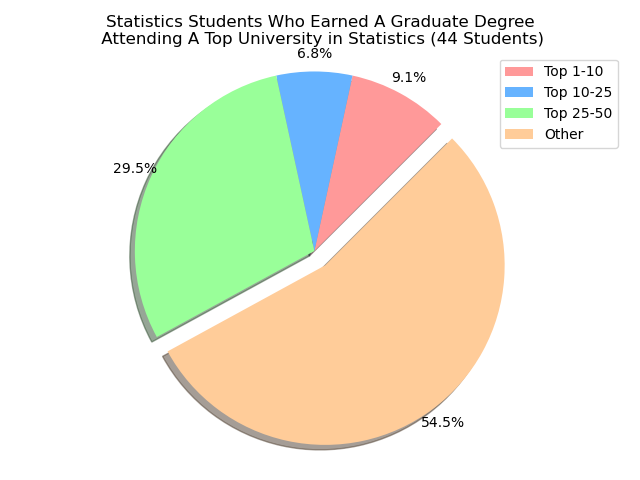
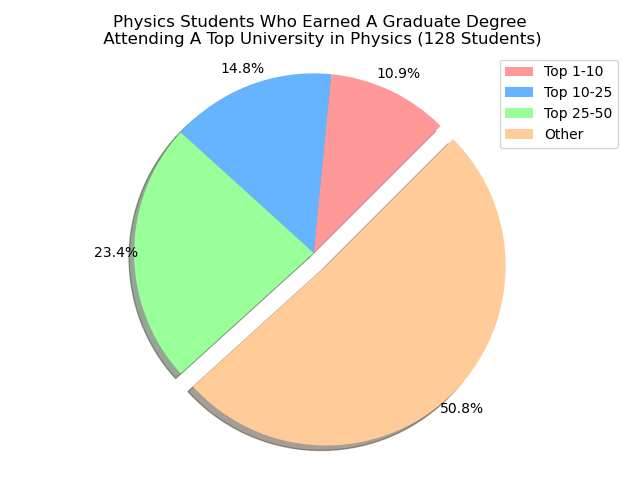
Do Our UCSB Alumni Receive Their ‘Graduate’ Degree From a Top 10 University For Their Specific Discipline?
Respective Rankings¶
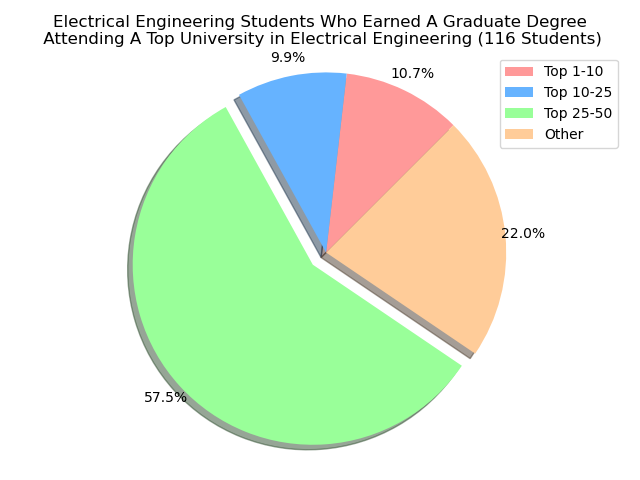
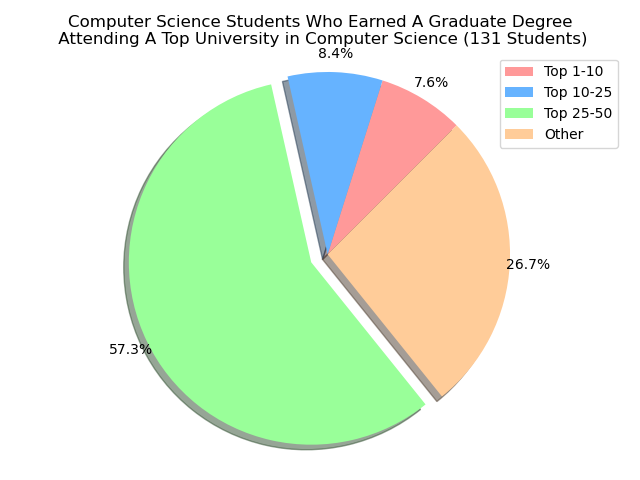
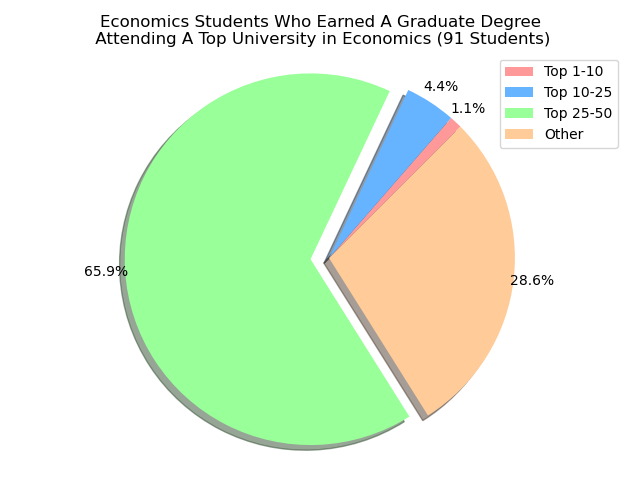
There is a lot of wonder where our UCSB alumni actually earn their ‘Graduate’ degree from. Particularly, we’re looking at students who went to a university that was a top-tier school for what they were studying in. For instance, if we were looking at students who earned their ‘Graduate’ Degree under a Computer Science discilpline, then we want to see if that university is a top-tier university for Computer Science.
To keep in mind on the rankings, we pulled from usnews.com under their best graduate degree programs for specific majors. We were able to do that for a few choices: Electrical Engineering(2020 list), Computer Science(2018 list), Economics(2017 list), Statistics(2018 list), and Physics(2018 list). Our goal would be then to utilize a machine learning algorithm to be able to predict of the XX students who earned their ‘Graduate’ Degree under a XY discipline, then we can predict a subset of those XX students will attend a top-10 university for their discipline.
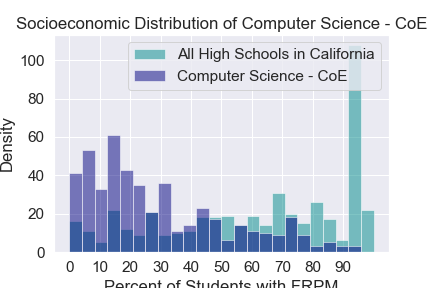
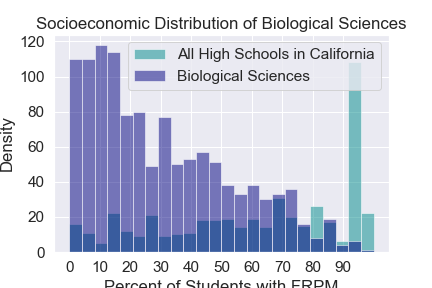
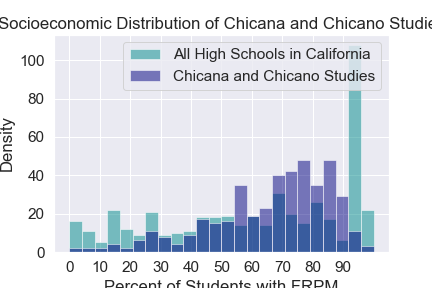
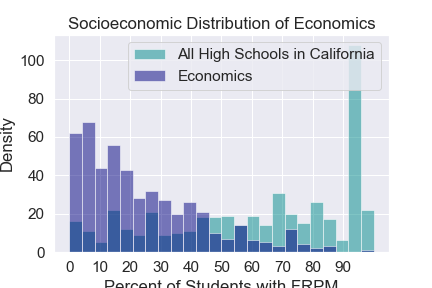
Socioeconomic Distribution by Major¶
The percent of students who are eligable to recieve free and reduced lunch (FRPM) at a particular high school is a good metric for the socioeconomic status of the studnets who attend that high school. Using publicly availibe data we can find the FRPM distribution of high schools across California. Looking at the high schools of studnets from various majors we can see how the FRPM distribution of a certain major compares to FRPM distribution of high schools across California. In general we see that STEM majors are highly selective for studnets from highschools where most students aren’t eligable for free and reduced lunch.
Software Used¶
Python
SCRE
Excel